Calibration (predicted vs. observed)
Ranking well is not enough.
A risk assessment tool can rank people correctly and still produce inaccurate probabilities. That is where calibration comes in.
A tool can rank people well and still produce misleading probabilities.
What Calibration Means
Calibration asks a different question than AUC:
In a well-calibrated tool, predicted risk closely matches what actually happens. For example, a predicted 30% risk corresponds to about 30% observed recidivism.
Calibration compares prediction to reality
A well-calibrated tool produces predicted probabilities that closely match observed outcomes.
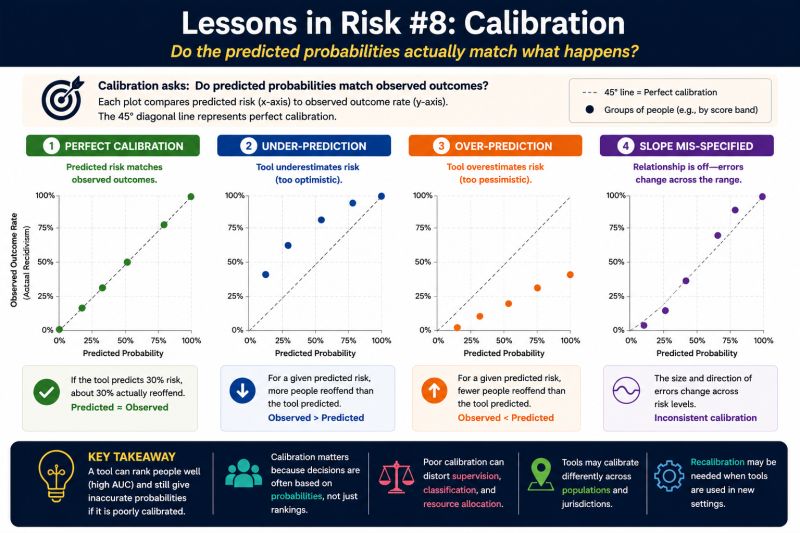
Calibration asks whether predicted risk matches what actually happens across different score levels.
How Tools Mis-Calibrate
Tools can mis-calibrate in different ways:
- Under-prediction → actual outcomes are higher than predicted
- Over-prediction → predicted probabilities are too high
- Mis-specified slopes → errors change across risk levels
Why This Matters
- Decisions are often based on probabilities, not just rankings
- Poor calibration can distort supervision and classification decisions
- Tools may calibrate differently across populations and jurisdictions
Why Recalibration Matters
If a state or agency has adopted a tool developed elsewhere, has its calibration been evaluated?
Tools may perform differently when moved to new settings, populations, or jurisdictions.
Bottom Line
A tool can rank people well and still produce misleading probabilities. Calibration asks whether predicted risk actually matches observed outcomes.
Zachary Hamilton
Professor
My research centers on innovation in risk and needs assessment development.